AWS Spot instances allow cloud customers to bid on spare compute capacity. This is a win-win for Amazon and customers: Amazon gets extra revenue on otherwise idle instances, and customers can drastically reduce compute costs for services that are tolerant of interruption. AWS makes this process easy by offering tooling to create and manage fleets of spot instances, but constraints in Amazon’s compute infrastructure, combined with sub-optimal use of spot instances by other customers, leaves opportunity when selecting instances.
Anyone familiar with spot instances knows that it can be advantageous to select from multiple similar instance types, selecting the cheapest or diversifying to improve availability. But in some cases, it may not even be necessary to reach for similar-enough instances: amazon’s spot market often prices instances that are strictly more powerful for less money. By looking at this mispricing, we can gain a better understanding of how Amazon is provisioning infrastructure under the hood, and save an average of 15% on existing spot prices when instances are mispriced.
EC2 Instance Families and Equivalent Instances
EC2 instances are divided into families. Each family has consistent architecture, underlying hardware, and rough performance per core, and has instance types of with varying CPU and memory. Within a family, each instance type has a set ratio of CPU to memory: compute-optimized instances simply have less memory per core (and sometimes slightly better CPUs), and memory-optimized instances have more memory per core. Each instance type is noted by its family (generation, what it’s optimized for, architecture, and any other features), and size in CPU cores. For instance, a c6gd.12xlarge is a Compute-optimized, 6th-generation Graviton instance with an NVMe Drive, and 48 cores (xlarge is 4 cores).
Within these instance families, we quickly see that some instance types are strictly better than others. Clearly (aside from benchmarking), a .12xlarge instance is always more desirable than a .4xlarge instance within the same family. But instance types across families can also be direct substitutes, and instances with storage are a direct substitute for those without. In theory, Amazon could ignore some CPU, memory, or disk resource when hosting a VM on the underlying hardware, and the VM would have no way of knowing. As we’ll see below, Amazon is almost certainly not doing that. By just modeling substitute instances that a strictly better than the desired instance, we can be sure that workloads deployed to substitute instances will have no issues running.
With some caveats, we can make the following substitutions:
- Any instance can substitute for instances in the same family of a smaller size.
- Compute-optimized (
C) instances can substitute for a general-purpose (M) instances of half the size, andMinstances can substitute forCinstances of the same size1. - Memory-optimized (
R) instances can substitute forMinstances of the same size, andMinstances can substitute forRinstances of double the size.
For example, you can make all these substitutions:
c6g.2xlarge→c6g.4xlarge→m6g.4xlarge→r6g.4xlarge→r6gd.4xlarge
If you’re looking to maximize your savings, you can likely also substitute later- and earlier-generation instance families, or different CPU vendors (Intel vs. AMD), but we’re going to focus on just those substitutions that Amazon could make transparently.
Spot instance mispricing
Taking a look at spot instance price history, we can pretty quickly discover instances of mispricing. Case in point:
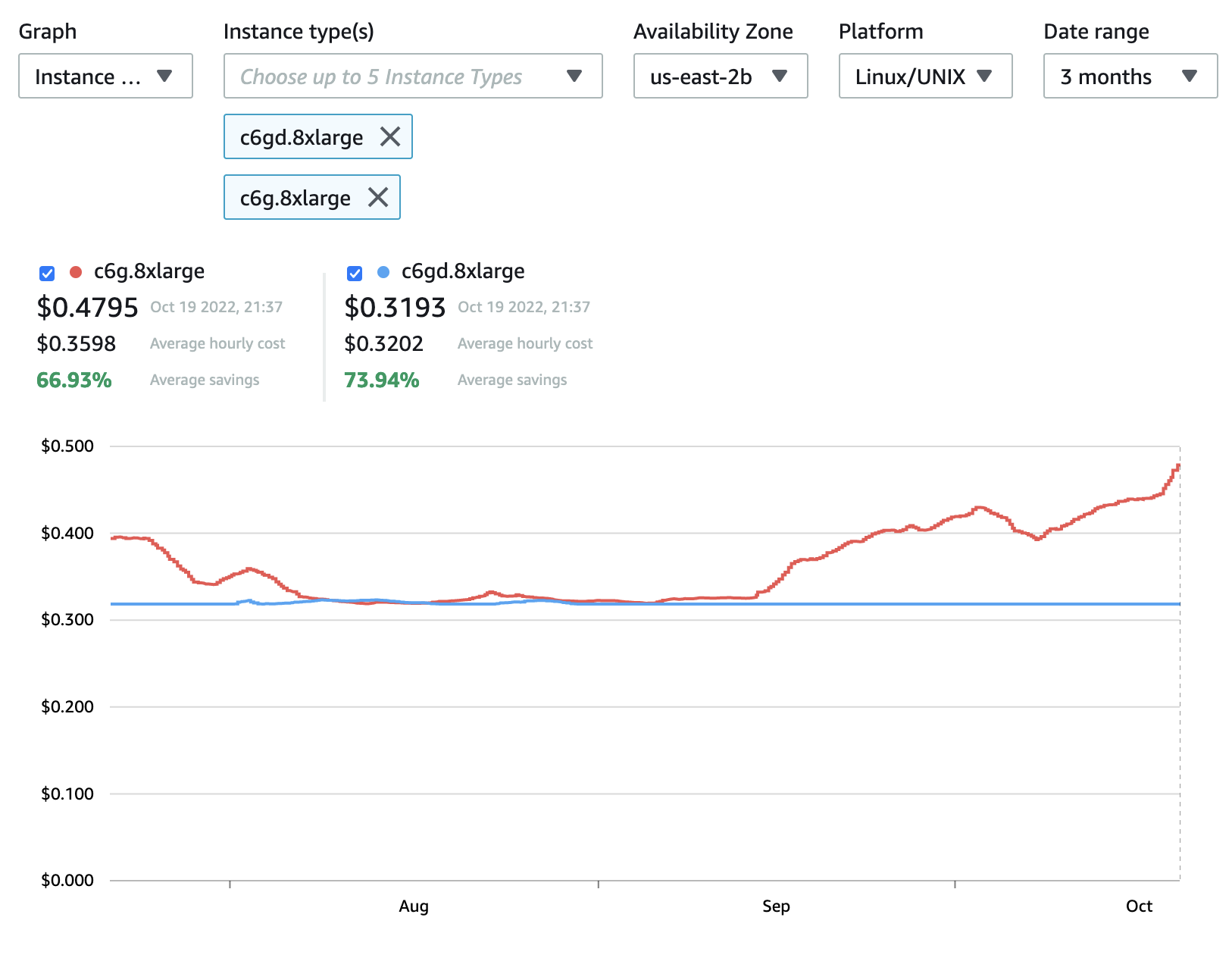
Here, we see the price of a c6g.8xlarge steadily climbing while the price of a c6gd.8xlarge stays relatively constant. Likely this is caused by naive customers bidding on c6g instances directly, instead of specifying their compute requirements and accepting the equivalent c6gd instance. Clearly, the market is not operating efficiently, and we can take advantage of that to get better instance pricing.
Next, let’s figure out just how prevalent this mispricing is, analyzing data across all AWS regions.
Measuring spot mispricing
At this point we’ve shown that spot pricing isn’t perfectly efficient, but just how inefficient is it, and how much can we save by taking advantage of this? To answer these questions, we’ll analyze pricing data from 3 months across all AWS regions. As before, we’ll limit analysis to substitute instances that are strictly better than the desired instance.
We’ll look at time-series data across regions. When processing historical pricing data, we track which substitute instance is cheapest for every spot instance type, then compute the potential savings in percent and absolute terms. We’ll also track what percentage of instance types are mispriced in each availability zone, region, and geography. First, let’s look at mispricing by geography:
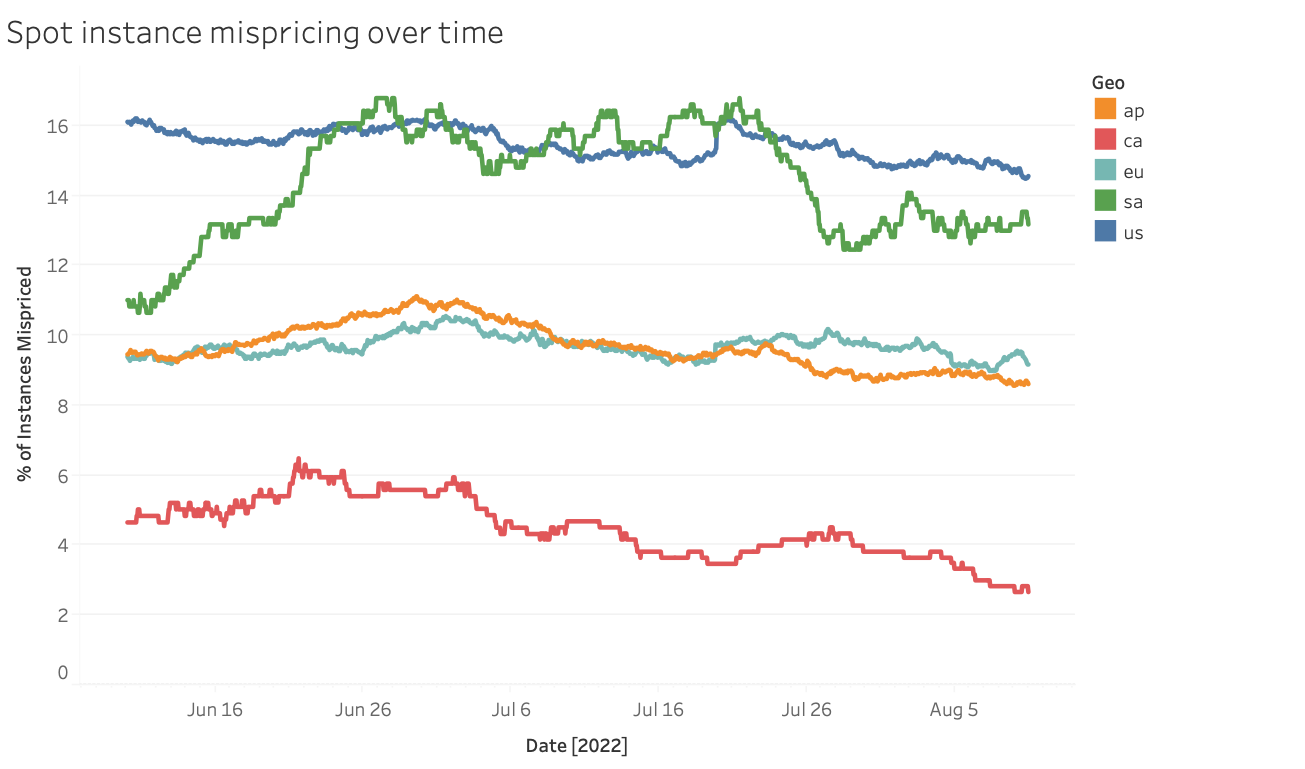
There’s a lot of aggregation going on here! Each series represents the percentage of instance types that are mispriced (i.e., some other instance type is better and cheaper) across all regions and availability zones in a given geography. We see some broad trends, as as US and South America having the highest rate of mispricing. Overall, 11% of instance types are mispriced. But this doesn’t tell the whole story, as each region (and availability zone!) has its own spot market:
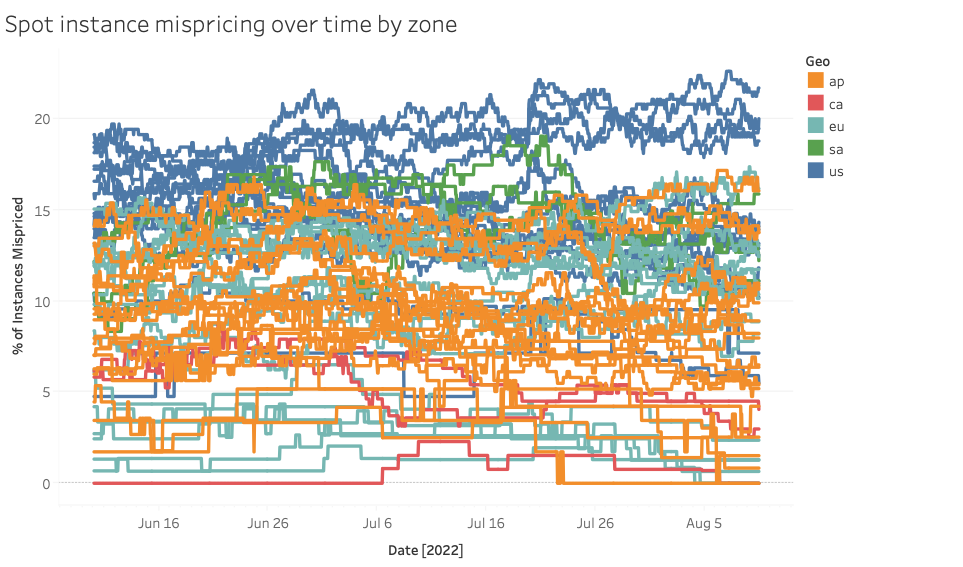
Results here are all over the place, but one group of zones is by far the most mispriced. These zones (blue at the top of the graph) are all in us-east-1, the original and largest AWS region. Generally, it looks like the bigger the zone, the more potential mispricing there is! This is a little counter-intuitive as we’d expect the thicker market of larger regions to improve on these price inefficiencies. Perhaps percent of instances mispriced doesn’t tell the whole story; let’s look at the actual average discount of the cheapest substitute instance for mispriced instances:
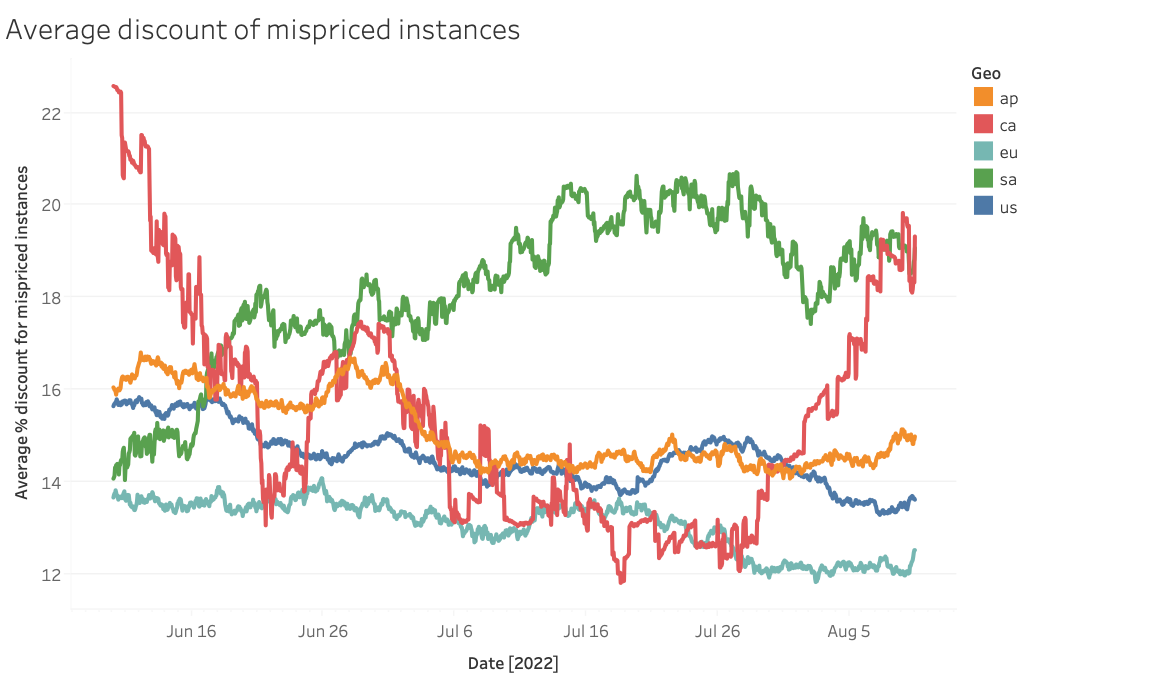
Here we see an opposite (and more intuitive) effect! Larger regions may have more mispriced instance types, but the average price discrepancy is indeed lower, in line with what we might expect in a thicker market. Among mispriced instances, around 15% can be saved on average by switching to a substitute instance that is strictly better.
Estimating overall mispricing
Next, we’ll try to (roughly) estimate the total amount of mispricing going on across all of AWS. To do this, we’ll look at the absolute difference in instance pricing (in dollars, instead of percent) across types, and then take a wild guess at the number of overall spot instances. From this, we’ll see how much more money Amazon could (theoretically) make by reselling substitute instances on the spot market. Let’s look at overall price discrepancy across geographies:
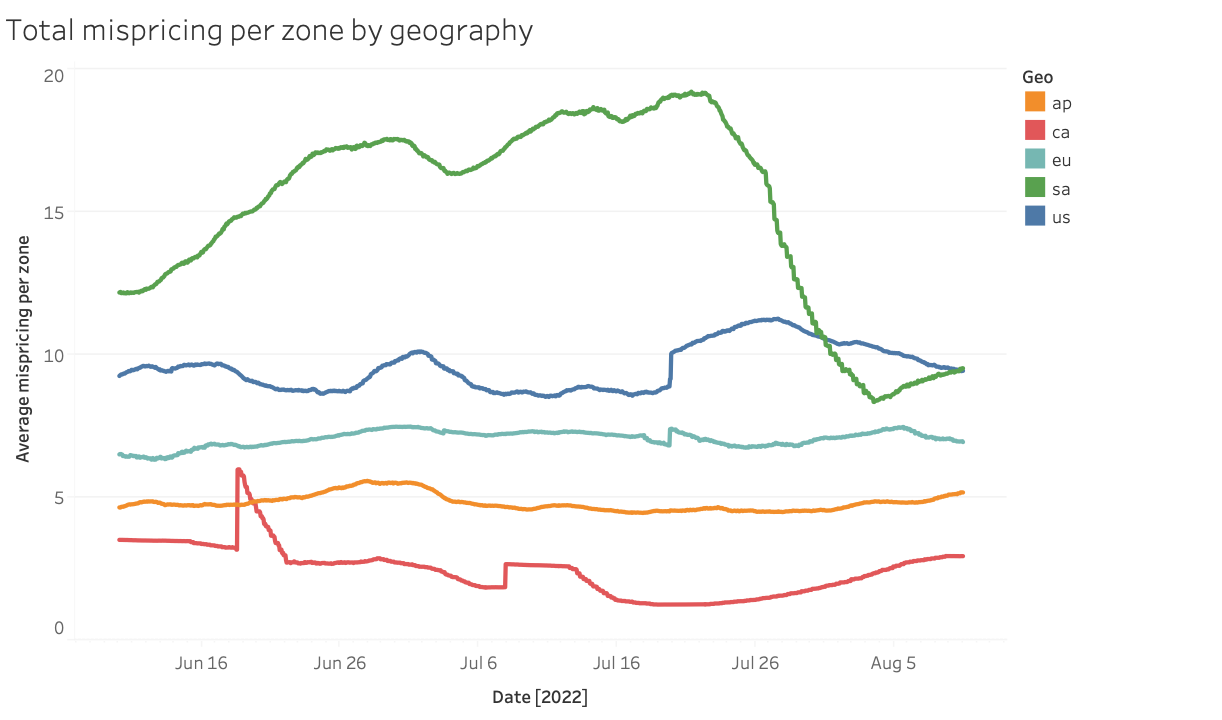
Mispricing varies over time, but averages between $5-10/hour per availability zone. This number means that, if a single instance of each type is mispriced, the instances are being sold for $5-10/hr less than the could be. Of course, in reality Amazon couldn’t make up that entire amount by reselling the instances under a different type, as this would move the market. Instead let’s assume they could recoup half that amount, a conservative estimate as substitute instance types are usually less popular types (larger or with attached disks).
Across all AWS availability zones instances are mispriced by roughly $400/hr at any given time. This means that, with just a single instance of each type, Amazon is missing out on $200/hr or roughy $1.7 million each year. This is over roughly 15,000 pools of instances. Given Amazon controls roughly 100 million IPs, we can guess that each instance pool probably has on the order of 1000 instances (more for smaller instances, less for larger instances). Given this, the average mispriced pool might have hundreds of instances, meaning hundreds of millions each year in missed revenue due to mispriced spot instances. Because amazon keeps their number of instances a secret, it’s difficult to make a precise estimate from the outside, but the missed revenue probably falls somewhere in this range.
Explaining spot mispricing
EC2 instances make up a large portion of profit for the world’s largest cloud provider, so there’s no doubt Amazon has thought a lot about the market economics here. Given that, there is likely a good reason why Amazon doesn’t resell instances under different IDs. A few come to mind:
- Complexity. Amazon’s current setup likely contains homogeneous sets of instances within a given server, and there could be deep architectural assumptions that would be violated by changing this.
- Hidden differences. There may be hidden differences in the underlying hardware that are not immediately apparent to customers, but that would cause issues if hardware were reused under other instance types.
- Expected workload. Instances provisioned under a given family may tend to have certain characteristics that Amazon plans around. For instance, a compute-optimized instance may have lower disk I/O than a memory-optimized one, and this could be used for planning.
- Minimal benefit. While the missed revenue appears large in absolute terms, it may simply be too small for Amazon to optimize around, especially given the other points.
Minimizing Spot Costs
With all this said, the lingering question is how to leverage this mispricing to reduce costs. The most important trick here is to be flexible about your instance types, and think outside the box. Example launch specifications from Amazon use only single instance types, and while multi-availability-zone deployments may make this acceptable, accepting broad families and sizes of instances will allow a spot request to be filled at the lowest possible price. For instance, this spot request specifies attributes and automatically allows instance types of larger sizes or with disks:
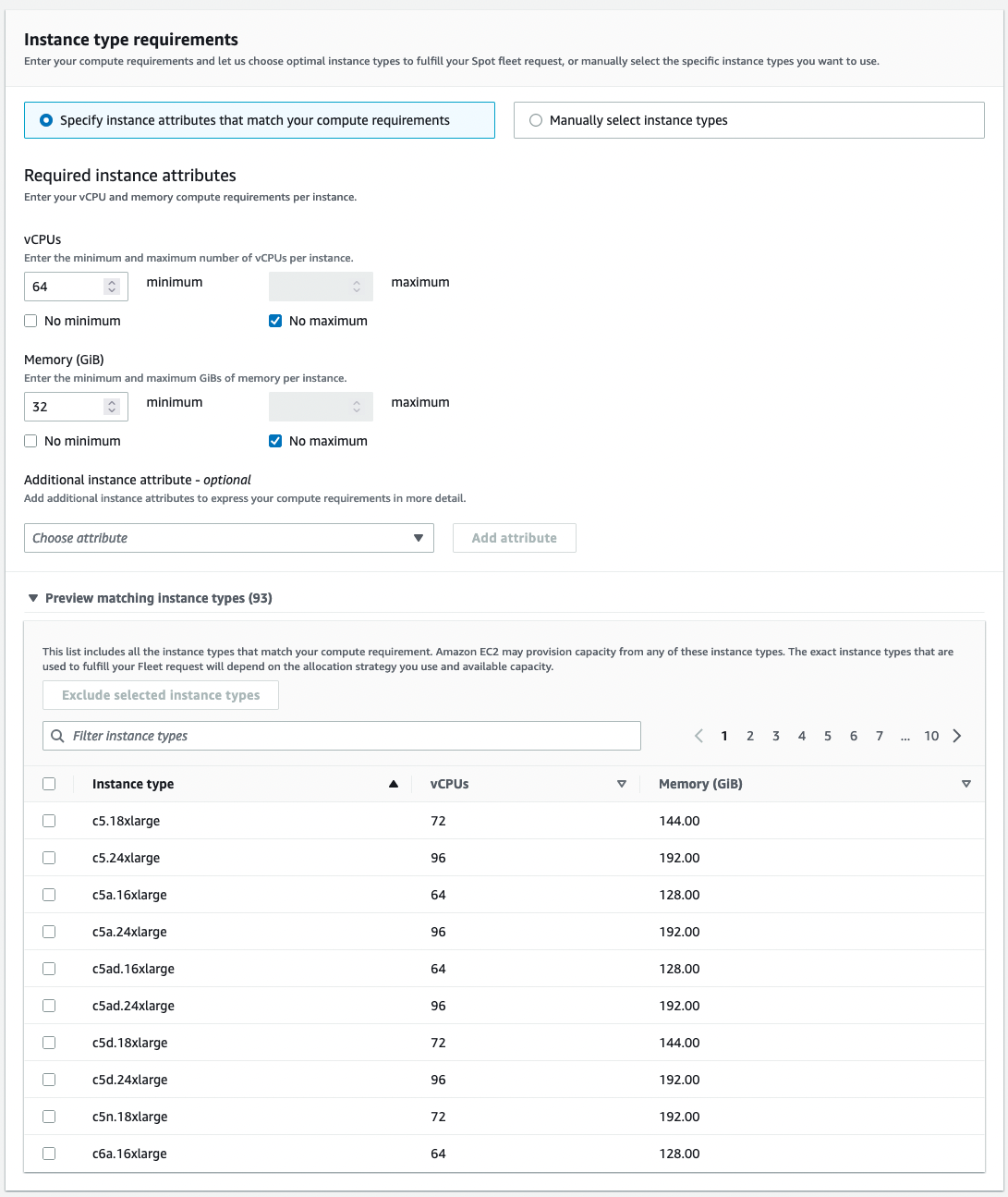
You can use features such as Spot price protection and Lowest price allocation to ensure compatible expensive instances don’t cause you to go over budget. By using instance attributes instead of families we can take advantage of market inefficiencies to save money!
The spot market is vast and complex, and as we’ve seen it often contains inefficiencies that create unexpected deals on equivalent instance types. By crafting intelligent spot requests, we can reduce costs while getting equivalent or better performance.
-
4th and 5th generation compute instances have slightly different processors in compute, so this doesn’t work ↩︎